One of the main goals of bio-design for the real-world is to enable large-scale sharing of environmental data gathered by citizen scientists. We envision in particular that the collected data could be visualized on a geographical map. In fact, several citizen science projects started in the past few years already focus on environmental/urban/civic data mapping . Here are just a few.
- http://aircasting.org/ aims at being a map of air pollution. The data is collected by a sensor that leverage the now ubiquitous smartphones to upload the data in real-time.
- http://blog.safecast.org/ started after the Fukushima nuclear accident. The data is collected by sensors fixed on cars. The data is uploaded through an API or directly on a website.
- http://596acres.org/ collects and displays data about empty plots of land in New York City.
Many of these projects share their code as open-source projects. If possible, we would not like to reinvent the wheel. However, it is sometimes more difficult to adapt an existing system to one’s needs than to start from scratch. We need thus to carefully evaluate the needs and aims of our platform.
The map
There are several types of data and they come with various degrees of difficulty to be visualized or displayed on a map. Let’s see a few examples, from easiest to most difficult.
- Radiation. Radiation is, at its simplest, a textbook example for data mapping. Using a Geigier counter (calibrated to a known source, usually by the manufacturer), it is possible to obtain the value of the dose rate, i.e. how strong the radiation field is (more subtle measurements are possible). There is a simple interpretation for the data as a lower number generally indicates a lower risk. Adding the geographical position, we have three dimensional data that can be easily displayed as an intensity color map overlayed on a geographical map. This is e
 xactly what Safecast does.
xactly what Safecast does.
The color overlay works well here because the data is inherently continuous, that is each spatial location on Earth has radiation that we can measure. It makes thus sense to display information everywhere.
Another property of the Safecast dataset is that nearly all measures are made with the same measurement system. This allows to keep the amount of metadata (e.g. measurement protocol, instrument calibration, etc) to a minimum.
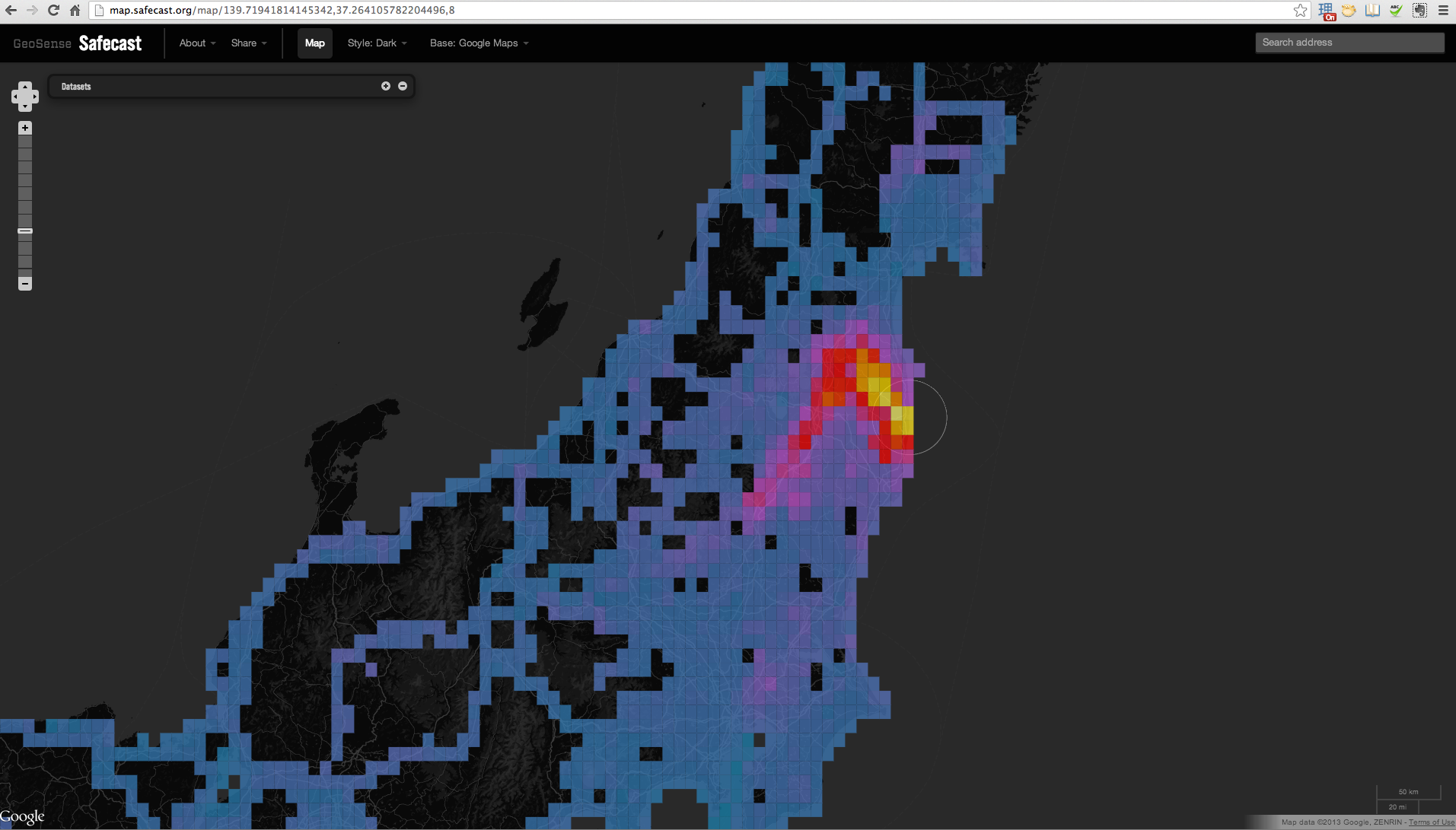
- Air pollution. The case of air pollution is more complicated. There can be several problematic pollutants in the air (particulate matter PM2.5, NO2, SO2, etc). Each of them requires a distinct callibrated sensor and it is not clear how these measurements should be combined. Generally speaking, higher measurements are worse for all. Aircasting make the choice of only measuring PM2.5 and applies a similar approach as Safecast for the mapping. Here again the data is continuous and an overlay works well.
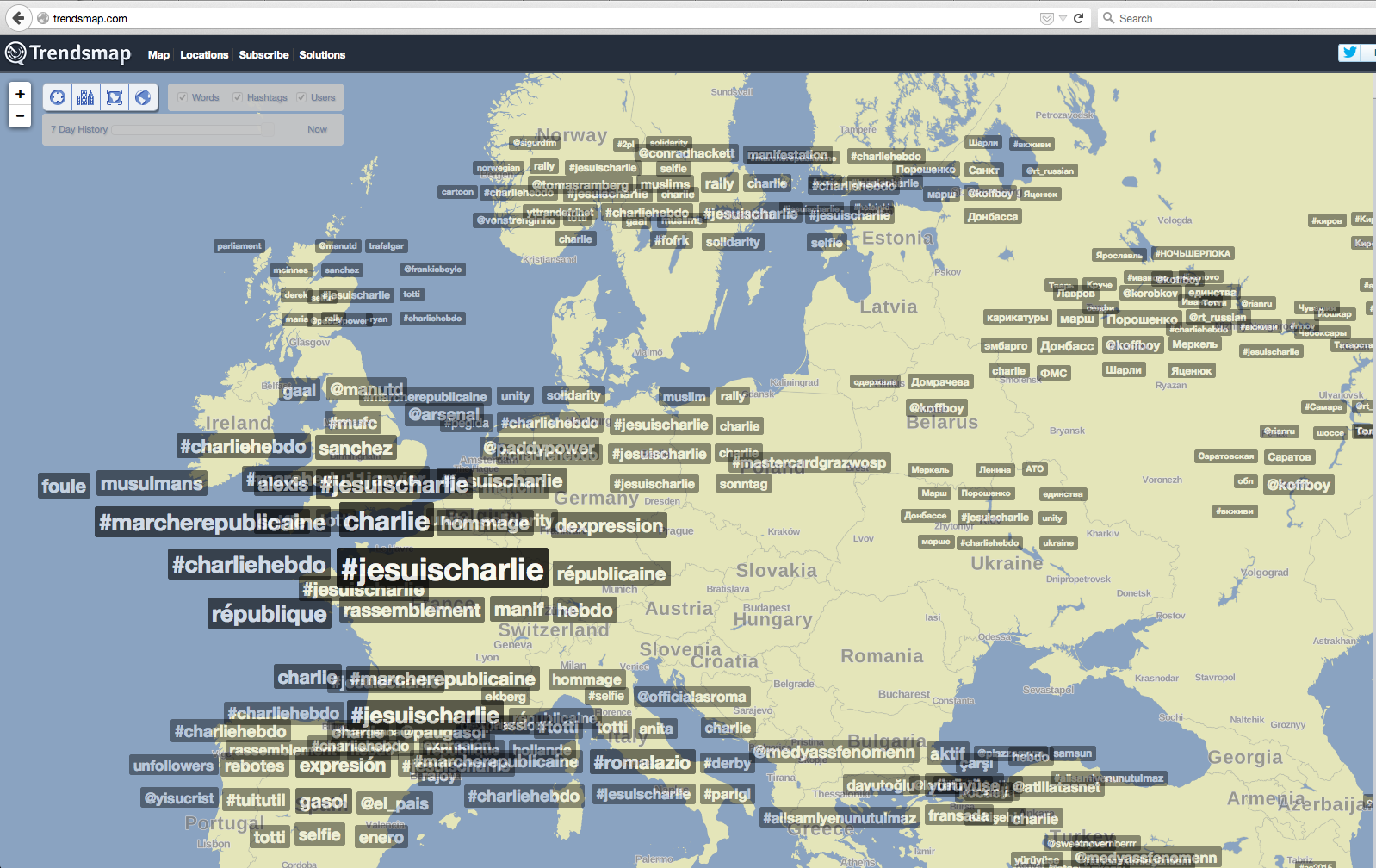
- Twitter hashtags. Here we are dealing with non-numerical data. Trendsmap uses the font size and
 transparency to indicate the importance of a hashtag. The placement on the map indicates the geographical location of the trend. Here the underlying data (tweets) is discrete (isolated events, tweets), but we expect the trends described by the hashtags to be continuous (spread to a large area, or number of individuals. The value of data points (#hashtags, text) is non-numerical and cannot be displayed as a smooth image to represent the area the trend covers. Thus discrete points must be used.
transparency to indicate the importance of a hashtag. The placement on the map indicates the geographical location of the trend. Here the underlying data (tweets) is discrete (isolated events, tweets), but we expect the trends described by the hashtags to be continuous (spread to a large area, or number of individuals. The value of data points (#hashtags, text) is non-numerical and cannot be displayed as a smooth image to represent the area the trend covers. Thus discrete points must be used.
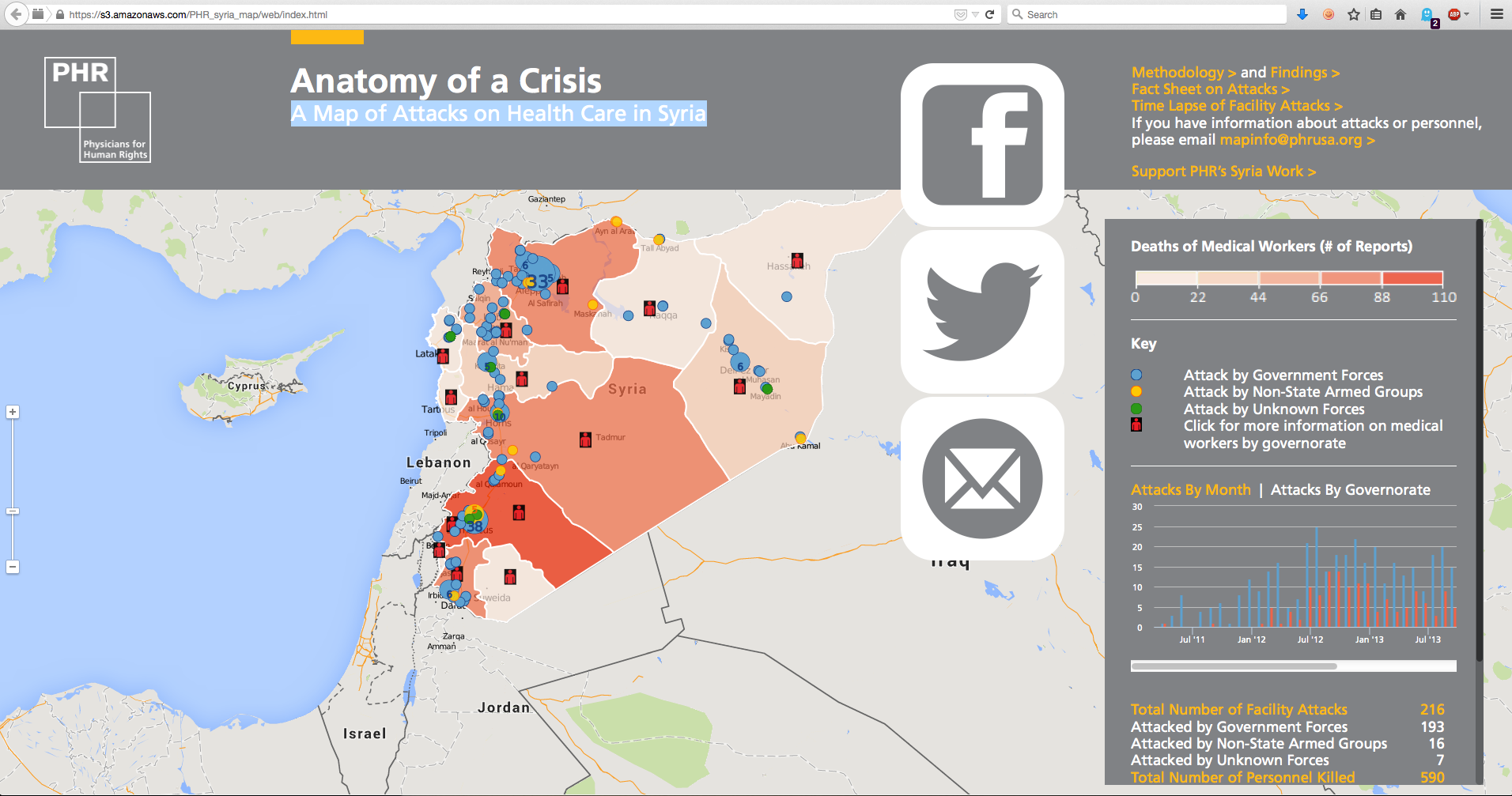
- Attacks in Syria. This map displays the number of attacks on healthcare workers in Syria. The geographical location is indicated by a dot (because the events are at discrete locations). The size of the dot is proportional to the number of persons hurt in the attack (numerical data). The color of the dot indicates which faction carried out the attack (non-numerical data). In addition the map contains information about the state borders and each state is colored according to the total number of persons injured by attacks in that state (numerical).

- Hydrochemical analysis of ground water in Vietnam. Some maps and data collected by EAWAG. Here we have a massive scientific analysis. Over thirty compounds are measured at various locations. The data is displayed on several maps (one per compound). This survey shows the complexity of water analysis. The sampling points are discrete, however, the underlying water ground network is not. It is not simply a 2D surface, it is a mix of lines (rivers) and 2D surfaces (lakes, sea). There is significant migration between locations and we can suppose that the measurement at one sampling location is linked to several other locations in the network. The quantities of compounds required to observe health effects are very small and thus complicated protocols and instruments must be used, requiring a lot of additional meta-data (numerical and non-numerical). In addition, some of the measurements might themselves be meta-data for another type of measurements. For examples, the presence of one compound in the water might affect the measurement of another type of compound.
The last example gives a good idea of the type of data we expect to collect with Bio-Design for the Real-World.
The design criteria
- One measurement is a numerical value and its unit.
- Several measurements can be taken at a single sampling point. The sampling point contains the location coordinates as well as meta-data concerning the type of measurements, GPS device used, etc.
- We would like to be able to also attach meta-data and non-numerical data to a sampling point.
- One measurement can be:
- One value.
- Several values.
- A pair of values.
- Several pair of values.
- etc.
- If we can also associate a single value to one sampling point, some kind of overall quality index, it is possible to create a simple color map overlay leading to an intuitive comprehension of the map.
- We would like to be able to select sampling locations according to arbitrary criteria, such as administrative boundaries, countries, measurements values, etc.
- Possibility to upload massive amounts of data in the form of text files for examples.
- Programmatic access through an API so that sensors can upload directly the data if they have internet access.
- Make the database design independent of the data collected. For each new data type, a new module can be developed for the back end. Making it easy to add support for new types of sensors.
- We need to find a trade-off between modularity of the database design and performance. We would like to avoid to have joins on large tables for each display of the main map for example. An idea could be to store a few of the important measurements together with the sampling point record.
- Scalability. We would like to be able to display from a few to millions of data points. For this, it is necessary to aggregate the information before display when lots of points are to be included on the map.
The tools
At this point, we decided to develop our own system. After giving a try to Laravel, we decided to go for Django instead since it fully supports GIS in geodjango. The database of choice is of course PostGIS, an extension of Postgres that supports many useful datatypes and functions for geographical data. We are currently just beginning the development of the back-end, so expect more news on this topic soon!
